Evaluating the zero-shot verification abilities of GPT-4 on math problems
Recall the refinement problem tasks a model with predicting p(A | Q, D) where Q is a question, D is an initial draft solution, and A is a correct solution. This is a difficult task as it requires the model doing refinement to simultaneously solve several hard sub-problems. First the refiner must decide when to refine, i.e. whether the initial draft D is correct or needs further work. Then the refiner must decide where in the draft to begin refinement. This involves locating an error in the solution which ultimately results in the incorrect answer. Finally, the model must then decide how to fix the error by propsing the updated solution A.
Recent work [1] studies the ability of SOTA large language models to reliably refine answers to math problems without any external feedback e.g. from a human or code interpreter. They find most models struggle to even reliably decide when a draft should be refined, immediately bottlenecking performance. Even if a model can do this, it still must solve the strictly harder task of identifying precisely where an error occurs in a solution. We call a model capable of deciding when to refine and where to refine a verifier model.
In this work we examine the zero-shot abilities of SOTA LLMs (gpt-3.5-turbo-1106 and gpt-4-preview-1106) to act as both solvers and verifiers on GSM8K [2] and MATH [3] benchmarks. We note this evaluation is similar to work such as [4] which uses human annotated data to train a specialized step-level verifier for the MATH dataset. We emphasize the zero-shot verification abilities of current LLMs with a detailed error analysis examining where current models fail. In the process we benchmark several prompting strategies including single-token verification (in which the verifier outputs only a positive or negative token for the entire solution trace), Chain of Thought (CoT), and debate. Note that, in an effort to isolate models’ native reasoning abilities, we do not allow generators or verifiers to utilize a code interpreter.
Guided by our findings, we propose a new strategy we call multi-sample verification to improve the ability of general purpose LLMs to act as final-answer verifiers. This new method encourages the verifier to compare and contrast multiple diverse candidate solutions to the same question in-context, leading to improved performance in some cases. In comparison to current models, working mathematicians are extremely adept at gauging the expected outcome of proof strategies and detecting potential sources of error. This underscores the vital importance of improving verification capability for sophisticated LLM reasoning.
Part 1: Baselines for zero-shot verification
We begin by first getting a sense of the native abilities of gpt-3.5-turbo-1106 and gpt-4-preview-1106 as zero-shot verifiers. We do this by evaluating their accuracy on two benchmark datasets: GSM8K and MATH. To construct a test set for GSM8K we greedily sample gpt-3.5-turbo-1106 on all GSM8K test prompts, resulting in a dataset with 83% ‘positive’ label and 17% negative label. A verification test set for MATH is constructed similarly, with 43% of the candidate solutions labeled as “positive” and the rest as “negative”. Note, to save on api costs, we use a 1000 sample subset of the full 5000 sample MATH test set which we found to be representative. To evaluate correctness of final answers in GSM8K we use a similar parsing and extraction scheme as used in Minverva [5]. For MATH we use the same evaluation code as in [4].

We first evaluate several baseline prompting methods. These include single-step prompting, where the model generates a single ‘positive’ or ‘negative’ token following the (Q, A) pair, chain of thought, and a debate prompt where the model lists pros and cons of the solution before coming to a final verdict. When doing chain of thought we instruct the verifier to examine each invididual step of the solution before coming a final verdict. This is important, as otherwise even gpt-4 often produces a final verdict and then subsequent post-hoc rationalization. Exact prompts for each baseline can be found in prompts.py. All models are sampled at temperature T = 0. Results are reported below.
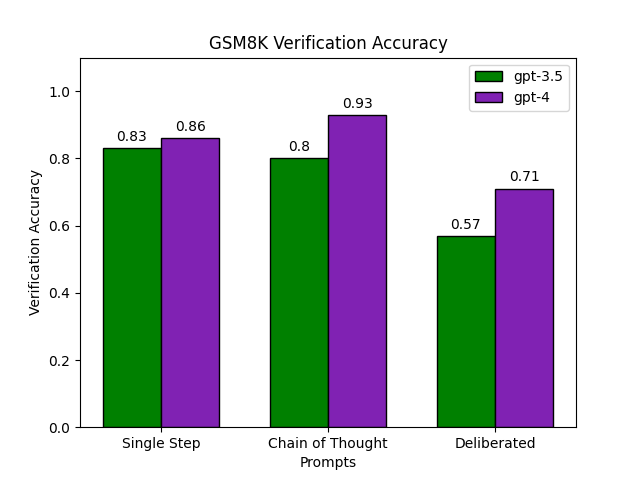
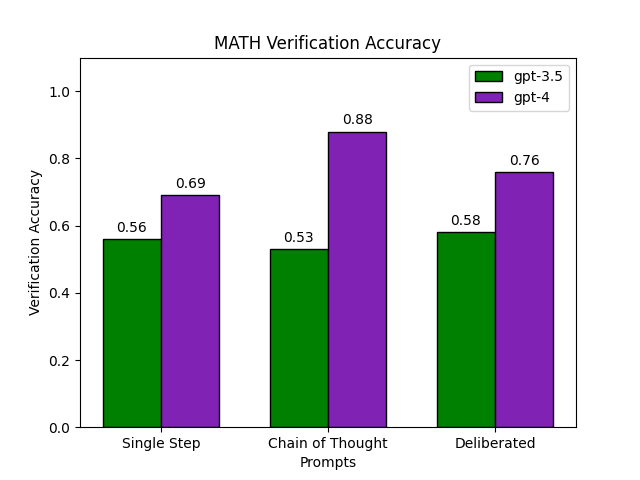
On GSM8K both gpt-3.5 and gpt-4 successfully verify the correctness of test problems with over 80% accuracy. gpt-4 in particular performs very well, successfully verifying 93% of solutions when going step-by-step. Curiously, forcing gpt-3.5 to make a single token prediction slightly increases verification accuracy. Yet verification accuracy for gpt-4 decreases by 8% without additional chain of thought. Deliberative prompting performs poorly, significantly reducing accuracy for both models. A qualitiative inspection of deliberated verifications suggests this approaches biases models to verify many solutions as incorrect. This is a disadvantage on GSM8K which has such an unbalanced proportion of valid solutions. On MATH gpt-3.5 as a verifier performs much worse. This is perhaps somewhat surprising as gpt-3.5 is able to successfully solve 41% of MATH problems, which one would hope suggests the model has some underlying understanding of what makes a solution valid. In contrast, gpt-4 again performs very well, correctly verifying up to 88% of candidate solutions. As with GSM8K, chain of thought prompting works best, with other methods dramatically decreasing performance.
To better understand why gpt-3.5 is performing so much worse than gpt-4 we can examine failure modes via precision and recall statistics.
| GSM8K | gpt-3.5 | gpt-4 |
|---|---|---|
| Precision | 0.86 | 0.96 |
| Recall | 0.91 | 0.96 |
| F1 | 0.88 | 0.96 |
| Predicted Correct | 0.89 | 0.81 |
| Actual Correct | 0.83 |
| MATH | gpt-3.5 | gpt-4 |
|---|---|---|
| Precision | 0.47 | 0.84 |
| Recall | 0.8 | 0.89 |
| F1 | 0.59 | 0.86 |
| Predicted Correct | 0.7 | 0.45 |
| Actual Correct | 0.41 |
Overall gpt-3.5 tends to be overly-lenient, classifying 89% of candidate solutions as correct when in reality only 83% are correct. This results in precision being non-trivially lower than recall. The gap is significantly worse on the MATH dataset, with gpt-3.5 achieving 0.8 recall but 0.47 precision. Clearly gpt-3.5 as a reasoning verifier admits a high rate of false positives by almost always classifying solutions as correct. A manual inspection of chain of thought verification traces also reveals this is the case at the step level: gpt-3.5 rarely criticizes intermediate steps. This behavior also explains why deliberative prompting works best in this setting as it induces a higher percentage of negatives. In contrast, gpt-4 appears extremely well calibrated on GSM8K. However, on MATH gpt-4 does admit more false positives than negatives. This suggests current LLMs in general are overly-lenient when verifying reasoning, likely overlooking crucial errors at the step level. This is the opposite of the kind of behavior we might want from a model capable of advanced mathematical reasoning. Ideally we want a low false-positive rate at risk of more false negatives.
With a better understanding of gpt-4 as verifier at the solution-level we next drill down to predictions at the step level.
Part 2: Step level verification
So far, we obtained our best verification results by encouragaging the verifier to inspect each line in a solution step by step, checking for an error. For gpt-4 this significantly improves performance over single-step verification. However, it remains unclear how good the verifier actually is at identifying errors at the step level. Intuitively, a verifier good at verifying the final answer should also work well when verifying intermediate steps. To evaluate our verifiers’ step-level accuracy we take solutions with step-level human labels gathered in [4] to train a process based reward model. We construct a verification test set for MATH by taking a 411 sample subset of the second round of prm data collected for the MATH test set. To ensure accurate evaluation, we filter out all questions whose answers we cannot reliably evaluate automatically. 59% of samples in the resulting dataset are valid solutions. Such solutions also have entirely positive intermediate steps. Incorrect solutions have positive intermediate steps up until the first negative step, after which all steps are negative including the final answer.
We prompt our verifier to verify step-by-step, explicitly producing intermediate labels l_1,...,l_L for all steps S_1,...,S_L in the candidate solution. For the exact prompt see prompts.py. We measure two resulting metrics. First, we measure the overall step accuracy at classisfying whether a step is positive or negative. Second, we measure the verifiers’ accuracy at predicting the first error location (if present) in a solution. We define the first error location of an incorrect solution as the number of the step containing the first mistake and the first error location of a correct solution as the total number of steps plus one. We additionally define the first error step offset as the difference in step location between the ground truth step error and the predicted step error, i.e. step_offset = loc(gt_first_error) - loc(pred_first_error).
| Model | Outcome accuracy | Step accuracy | Avg. first error offset |
|---|---|---|---|
| gpt-3.5 | 0.58 | 0.92 | 3.2 |
| gpt-4 | 0.75 | 0.74 | -0.62 |

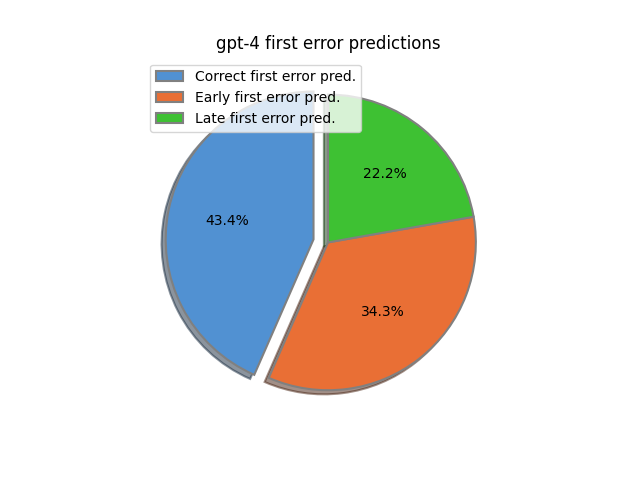
We find gpt-3.5 again performs poorly at verifying the final answer. Yet, it appears to have a very good overall step level accuracy. This is misleading, due to label imbalance and the fact that gpt-3.5 almost always verifies every step step as correct. For a similar reason, gpt-3.5 also appears to have decent first error accuracy: 59% of solutions are positive, resulting in solutions whose first errors never occur. gpt-3.5 correctly predicts the first error location of such solutions as the number of steps plus one. Thus we must instead look at results on the subset of negative solutions to get a better idea of how well gpt-3.5 actually does at identifying errors. Interestingly gpt-4 final verification accuracy on this test set is worse compared to earlier experiments. We hypothesize this is because the model generated candidate solutions of a higher quality than those generated by gpt-3.5, making it harder to identify obviously incorrect answers. At the step level, gpt-4 has a more balanced first error rate than gpt-3.5, despite having a lower overall accuracy. In particular gpt-4 has an average first error offset of -0.62, indicating gpt-4 predicts the first error slightly too early when averaged across both correct and incorrect solutions.
To better understand how both verifiers perform at detecting the presence of errors we now only evaluate on the subset of solutions containing mistakes.
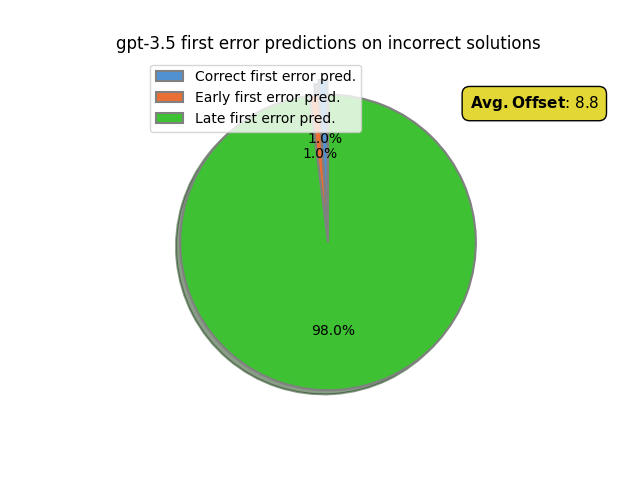
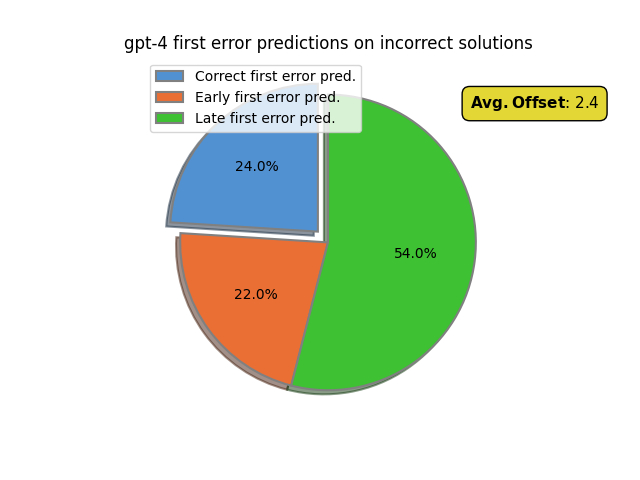
Looking at these predictions we see gpt-3.5 is essentially unable identify mistakes, failing 99% of the time. This is unsurprising as it nearly always verifies steps as correct. gpt-4 does nontrivially better, genuinely identifying 24% of first errors. Further, we can see that gpt-4 identifies most errors too late: around 54% of the time. In contrast, gpt-4 only “hallucinates” the presence of an error before it has occurred 22% of the time. This is somewhat intuitive, as even for human mathematicians the source of an error may not immediately be apparent. Yet downstream from the error it becomes easier to identify one has occurred as we can start to draw more obviously invalid conclusions. In gpt-4’s case this “realization” occurs on average 2.4 steps after the first error. This also partially explains the huge gap between final outcome accuracy, 75%, and first error accuracy. Even if gpt-4 is not able to correctly identify the location of the first error, it is able to detect some error has occurred down the line. This results in a “negative” final verdict.
Improving first error prediction via rechecking
Human mathematicians backtrack when confronted with obviously incorrect statements. This makes the task of detecting an error much easier, as now we can be sure an error does exist at or before the contradiction. gpt-4 does not perform this backtracking by default, but we can simulate this behavior through iterative prompting. In particular, once the verifier has produced intermediate step verifications and verified an entire solution as incorrect, we prompt it again to “recheck” its step-by-step work carefully with the knowledge there is an error somewhere prior to the first step previously identified as incorrect.
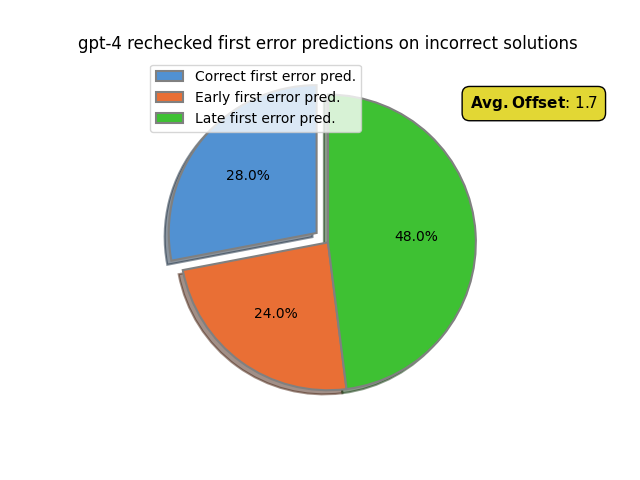
We find rechecking mildly improves the first error prediction accuracy from 24% to 28% (on subset of incorrect solutions). The percentage of late first error predictions also decreases from 54% to 48% as hoped. As a result the first error offset decreases from 2.4 to 1.7. This indicates rechecking does successfully improve the verifier’s ability to localize the first error, though perhaps not as much as we may have hoped. Nevertheless further use of iterative rechecking seems like a potentially promising direction for improving LLM step-level verification ability.
Part 3: In-context multi-sample verification
Our findings above indicate both gpt-3.5 and gpt-4 struggle to reliably identify both step-level and final-answer correctness on hard reasoning tasks. We now propose in-context multi-sample verification as one potential method of improving this capability with better prompting. The main idea is to condition the verifier on multiple diverse candidate solutions with the aim of comparing and contrasting possible reasoning errors in-context. For example, clearly if two solutions have differing final answers, then at least one of them must be incorrect. Formally, we ask the model to predict p(is_correct(A_1) | Q, A_2) where A_1, A_2 are candidate solutions and Q is the problem statement. Intuitively, we hope including multiple diverse solutions will encourage the model to compare and contrast all candidates, improving overall accuracy. We call this approach in-context multi-sample verification.
To construct verification test sets for GMS8K and MATH we sample gpt-3.5-turbo-1106 five times per test question (in the case of MATH we use the same 1000 question subset as before) at temperature T = 1.0. The resulting GSM8K solutions correctly solve the given questions 83% of the time. 40% of sampled MATH solutions are correct. We then select K = 2 solutions A_1,...,A_5 per problem, prioritizing pairs which result in different final answers to maximize solution diversity. To allow for comparability to our baselines, we randomly set A_i as the solution greedily generated by gpt-3.5. Note, however, we cannot always find diverse solutions for all questions, resulting in some pairs ending with the same final answer. At test time verifiers are then prompted with a question Q and two candidate solutions A_1, A_2 with instructions to compare and contrast both solutions at the step level before coming to final verdicts for both problems.
| GSM8K | gpt-3.5 | gpt-4 |
|---|---|---|
| Precision | 0.93 | 0.97 |
| Recall | 0.94 | 0.98 |
| F1 | 0.93 | 0.97 |
| Predicted Correct | 0.81 | 0.83 |
| Actual Correct | 0.83 |
| MATH | gpt-3.5 | gpt-4 |
|---|---|---|
| Precision | 0.5 | 0.77 |
| Recall | 0.85 | 0.92 |
| F1 | 0.63 | 0.83 |
| Predicted Correct | 0.67 | 0.49 |
| Actual Correct | 0.41 |
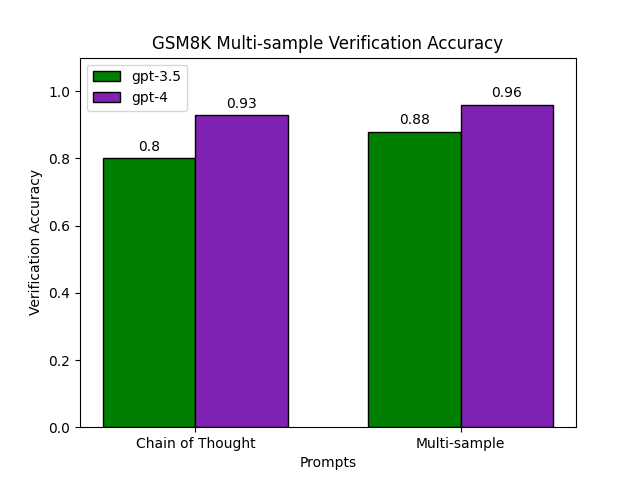
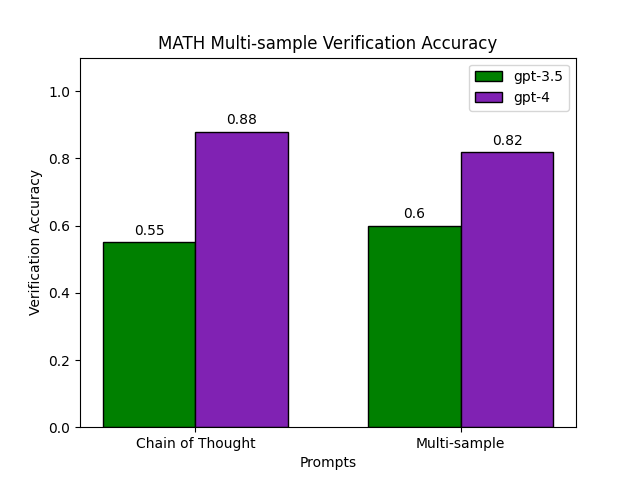
On GSM8K multi-sample verification improves both gpt-3.5 and gpt-4 predictions, in particular significantly improving gpt-3.5 from 80% to 88% accuracy. As desired, most of this increase is due to precision improving from 86% to 93% while also simultaneously improving recall. I.e. multi-sample prompting seems to improve the verifier’s ability to recognize incorrect solutions. Smaller improvements are also seen for gpt-4. However, on the MATH benchmark, multi-sample prompting does not appear to have as much benefit. While gpt-3.5 experiences some improvement, gpt-4’s accuracy diminishes by 4%. Worse, most of this loss is due to a 7% drop in precision, with recall improving from 89% to 92%. This is a bit surprising, as somehow multi-sample prompting has increased the precision of gpt-3.5 but decreased gpt-4’s precision. We speculate this is likely because simultaneously considering two candidate solutions increases the likelihood of the LLM to judge at least one as incorrect. This benefits a verifier like gpt-3.5, which struggles to reliably critique invalid reasoning, but seems to benefit gpt-4 less on a harder benchmark like MATH. We also find the ordering of solutions significantly impacts the label the verifier assigns, with solutions later in the context more likely to be labeled as incorrect.
Evaluating gpt-4 as an in-context reranker
To better understand how well gpt-4 is able to handle multiple solutions in-context we also evaluated its ability to act as a reranker on MATH. To construct a test set we sample gpt-3.5-turbo-1106 K = 5 times at temperature T = 1.0 on our 1000 question subset of the MATH test set. We then filter out questions for which the correct final answer was never reached in any of the five samples. This leaves us with 526 samples remaining. We then prompt gpt-4 to act as an in-context reranker by putting all five solutions in-context and prompting gpt-4 to choose the most promising. As a baseline we additionally consider maj@5 score and measure the agreement bewteen gpt-4 and the maj@5 selected final answer.
| rerank@5 | maj@5 | pass@5 | Rerank maj. agreement |
|---|---|---|---|
| 0.8 | 0.78 | 1.0 | 0.74 |
Overall gpt-4 performs about the same as maj@5 with a 80% versus 78% successful selection rate. Interestingly, despite having similar accuracies, gpt-4 disagrees with majority votes on the correct final answer 25% of the time. This is somewhat surprising, as an easy failure mode for gpt-4 to fall into would simply be choosing the most popular final answer.
Conclusions
In this post we took an in-depth look at the verification abilities of SOTA large language models (gpt-3.5-turbo-1106 and gpt-4-turbo-1106). In addition to being useful for refinement, the ability to gauge a solution’s correctness and localize errors is crucial to a deeper understanding of mathematics beyond mere imitation of valid proof. We found that all models tend to be overly-lenient, admitting undesirably high rates of false positives. Additionally, at the step-level, verifiers struggle to correctly identify the first error, getting less than 30% accuracy even after being allowed to re-check their verification for mistakes. This suggests even SOTA LLMs have a long way to go towards achieving truly expert level understanding on complex reasoning tasks.
Acknowledgements
Many thanks to Daniel Paleka and Louis Castricato for providing detailed feedback on a draft version of this post.
References
-
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models can- not self-correct reasoning yet. ArXiv, abs/2310.01798, 2023. URL https://api.semanticscholar.org/CorpusID:263609132
-
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Rei- ichiro Nakano, Christopher Hesse, and John Schulman. Training veri- fiers to solve math word problems. ArXiv, abs/2110.14168, 2021. URL https://api.semanticscholar.org/CorpusID:239998651.
-
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Xiaodong Song, and Jacob Steinhardt. Measuring mathe- matical problem solving with the math dataset. ArXiv, abs/2103.03874, 2021. URL https://api.semanticscholar.org/CorpusID:232134851.
-
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. ArXiv, abs/2305.20050, 2023. URL https://api.semanticscholar.org/CorpusID:258987659.
-
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Hen- ryk Michalewski, Vinay Venkatesh Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning prob- lems with language models. ArXiv, abs/2206.14858, 2022. URL https://api.semanticscholar.org/CorpusID:250144408.
Cite this post as
@misc{havrilla_2024_10794598,
author = {Havrilla, Alex},
title = ,
month = mar,
year = 2024,
publisher = {Zenodo},
doi = {10.5281/zenodo.10794598},
url = {https://doi.org/10.5281/zenodo.10794598}
}
![]()